
The Hard Concept
Before a model can learn from text, the text has to become symbols. That symbol-making step is not neutral. It changes context length, rare-word behavior, code formatting, multilingual text, emojis, latency, and eventually model quality.
This first project in LLM Engineering From Scratch implements a tiny byte-level BPE tokenizer by hand. The goal is not to beat production tokenizers. The goal is to make the mechanism visible.
Mental Model
Byte-pair encoding starts with small pieces and learns bigger pieces from repetition.
In this project, the starting pieces are raw UTF-8 bytes. That means every string can be represented. Training repeatedly asks:
Which adjacent pair appears most often?
Then it merges that pair into a new token. After enough merges, common fragments become single tokens while rare inputs fall back to smaller pieces.
That is the important mental shift: BPE is not “splitting words.” It is learning reusable compression shortcuts from neighboring symbols.
Implementation
The scratch implementation has four core steps:
counts.update(zip(sequence, sequence[1:]))
First, count adjacent pairs across the training corpus.
if (sequence[index], sequence[index + 1]) == pair:
merged.append(sequence[index] + sequence[index + 1])
Then merge every non-overlapping instance of the selected pair.
Training repeats this loop until the vocabulary reaches the target size. Encoding new text starts from bytes and replays the learned merges in order.
The runnable implementation is in the GitHub repo:
Interactive Demo
This demo replays the BPE training trace. Scrub the slider to see which pair was selected, how the corpus changed, and how vocabulary size and compression ratio moved.
The demo uses a static data.json trace exported by the Python implementation. There is no server hiding behind it.
Results
The first chart compares how many tokens the larger BPE vocabulary used per character across several input types.
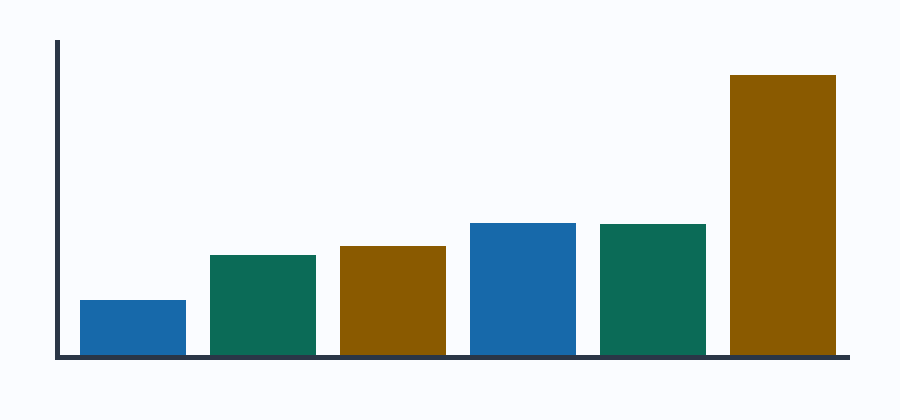
The second chart looks at token-piece byte lengths after encoding the stress examples.

These charts are intentionally simple. The point is evidence: tokenization changes can be measured, compared, and inspected.
Stress Cases
Stress cases covered:
- rare and invented words
- Python code with indentation
- math notation
- emojis
- multilingual text
The tokenizer round-tripped every example, but compression quality varied sharply. Common English-like text compressed better. Multilingual and emoji-heavy examples often fell back to byte-level pieces.
That is the tradeoff in one sentence: byte-level BPE is robust because it can represent anything, but it only compresses patterns it has learned.
Key Lesson
Unicode made the key lesson click. Some individual token pieces are not clean human-readable strings because a byte-level tokenizer can split inside a multi-byte UTF-8 character.
That looks ugly in a token-piece display, but it does not mean decoding failed. The original bytes are still preserved, so the full text round-trips exactly.
This separates two ideas that are easy to blur together:
- Reversibility: can the tokenizer recover the original text?
- Readability: do the intermediate pieces look nice to a human?
Byte-level tokenization optimizes for reversibility first.
Next Experiments
A useful next experiment is comparing this BPE implementation with a unigram/SentencePiece-style tokenizer on the same corpus, then repeating the experiment with a larger and more diverse dataset.
Another useful measurement is encode latency and context usage as vocabulary size grows. That makes the engineering tradeoff more concrete: fewer tokens can help context length, but training and encoding choices still matter.